
这是一篇关于AnimateDiff的文章,文章主要从几个方面介绍 AnimateDiff,包括什么是 AnimateDiff、如何在Stable Diffustion WebUI 中使用 AnimateDiff 等。本篇文章的内容主要翻译自 AnimateDiff 的github项目。
AnimateDiff
什么是 AnimateDiff?
这个扩展的目标是将AnimateDiff与CLI集成到AUTOMATIC1111 Stable Diffusion WebUI与ControlNet中。启用这个扩展后,你可以以与生成图像完全相同的方式生成GIF。
这个扩展以一种不同的方式实现了AnimateDiff。它不需要你克隆整个SD1.5存储库。它还对ldm进行了(可能是)最小的修改,因此如果你不想的话,不需要重新加载模型权重。
怎么在 Stable Diffustion WebUI 中使用 AnimateDiff?
-
更新您的WebUI到v1.6.0版本和ControlNet到v1.1.410版本,然后通过提供的链接安装这个扩展。我不计划支持旧版本。
-
下载运动模块并将模型权重放置在stable-diffusion-webui/extensions/sd-webui-animatediff/model/目录下。如果您想使用其他目录保存模型权重,请前往设置/AnimateDiff。查看模型库以获取可用的运动模块列表。
-
在设置/优化中启用"Pad prompt/negative prompt to be same length"并点击"应用设置"。您必须这样做以防止生成两个独立不相关的GIF。选择批处理条件/非条件是可选的,可以提高速度,但会增加VRAM的使用。
-
切勿禁用哈希计算,否则AnimateDiff将在您切换运动模块时出现问题。
WebUI 中使用
-
如果您想尝试 txt2gif,请前往 txt2img,如果想尝试 img2gif,请前往 img2img。
-
选择一个SD1.5的检查点,填写提示文本,设置配置,如图像宽度/高度。如果您想一次生成多个GIF,请更改批次数,而不是批次大小。
-
启用
AnimateDiff扩展,设置每个参数,然后点击生成。 -
您应该在输出画廊中看到生成的GIF。您可以在
stable-diffusion-webui/outputs/{txt2img或img2img}-images/AnimateDiff处访问生成的GIF输出。您还可以在stable-diffusion-webui/outputs/{txt2img或img2img}-images/{日期}处访问图像帧。您可以选择在Settings/AnimateDiff中将每次生成的帧保存到单独的目录中。
AnimateDiff 在 Stable Diffustion 中的参数与意义?
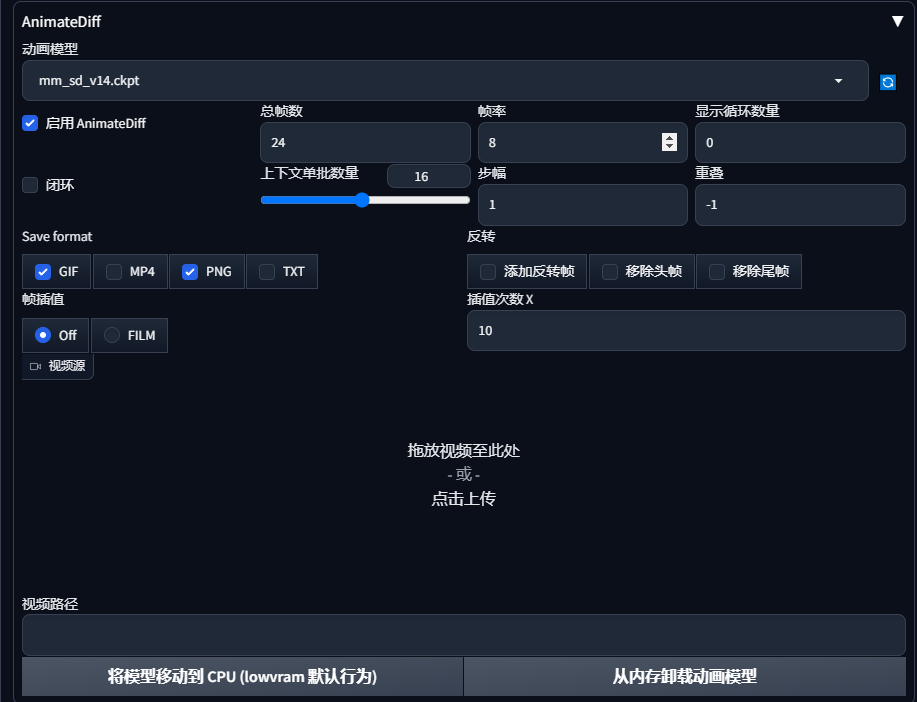
-
Save format - 输出的格式。至少选择一个:“GIF”|“MP4”|“WEBP”|“PNG”。如果您想要信息文本,选择"TXT",它将与生成的GIF保存在相同的目录中。信息文本也可以通过
stable-diffusion-webui/params.txt以及各种格式的输出访问。您可以使用
gifsicle(需要安装gifsicle,详细信息请参阅#91)和/或调色板来优化GIF(详细信息请参阅#104)。前往设置/AnimateDiff以启用它们。您可以通过设置
/AnimateDiff来设置WEBP的质量和无损选项。详细信息请参阅#233。 -
Number of frames(总帧数) - 选择一个你喜欢的数字。
如果你输入的是0(默认值):
- 如果您通过"视频源/输入视频路径"或"启用任何批量ControlNet"来提交视频,帧数将等于视频中的帧数(如果提交了多个视频,则使用最短的视频的帧数)。
- 否则,帧数将根据下面描述的上下文批处理大小确定。
如果您输入的帧数小于您的上下文批处理大小,但不是0,那么您将获得从整个生成中的第一帧到指定数量的帧数作为生成的GIF。随后的帧将不会出现在生成的GIF中,但会像往常一样保存为PNG。请不要将帧数设置为小于上下文批处理大小的值,除非出现问题#213。
-
FPS(帧率) - 每秒帧数,表示每秒显示多少帧(图像)。如果生成了16帧,以每秒8帧的速度播放,那么您的GIF持续时间将为2秒。如果您提交了源视频,您的FPS将与源视频相同。
-
Display loop number(显示循环数量) - GIF播放的次数。值为
0表示GIF永远不会停止播放。 -
Context batch size(上下文单批数量) - 一次传递到运动模块的帧数。SD1.5运动模块是用16帧训练的,因此当帧数设置为16时,会产生最佳结果。而SDXL HotShotXL运动模块是用8帧训练的。对于V1 / HotShotXL运动模块,可以选择[1, 24],而对于V2运动模块,可以选择[1, 32]。
-
Closed loop(闭环) - “闭环” 意味着这个扩展会尝试使最后一帧与第一帧相同。
i. 当"帧数"大于"上下文批处理大小"时,包括当启用了"ControlNet"且源视频帧数大于"上下文批处理大小"以及"帧数"为0时,AnimateDiff将执行无限上下文生成器的封闭回路。
ii. 当"帧数"小于或等于"上下文批处理大小"时,AnimateDiff无限上下文生成器将不起作用。只有当您选择"A"时,AnimateDiff才会将反转的帧列表附加到原始帧列表,以形成封闭回路。
-
Stride(步幅) - “最大运动步幅"作为2的幂次方(默认值:1)。这个选项用于指定运动模块的最大步幅,通常以2的幂次方来表示。
i. 由于无限上下文生成器的限制,这个参数仅在"帧数"大于"上下文批处理大小"时有效,包括当启用"ControlNet"且源视频帧数大于"上下文批处理大小"并且"帧数"为0时。
ii. “绝对没有封闭回路"只有在步幅为1时才可能。
iii. 对于每个 1 <= $2^i$ <= 步幅,无限上下文生成器将尝试使帧之间相隔 $2^i$ 个帧的时间保持一致。例如,如果步幅为4,帧数为8,它将使以下帧在时间上保持一致: 步幅 == 1: [0, 1, 2, 3, 4, 5, 6, 7] 步幅 == 2: [0, 2, 4, 6], [1, 3, 5, 7] 步幅 == 4: [0, 4], [1, 5], [2, 6], [3, 7]
-
重叠 — 上下文中重叠的帧数。如果重叠为-1(默认值):则您的重叠将是
上下文批处理大小// 4。- 由于无限上下文生成器的限制,这个参数仅在
总帧数>上下文批处理大小时有效,包括启用ControlNet且源视频帧数 >上下文批处理大小以及总帧数为0。
- 由于无限上下文生成器的限制,这个参数仅在
-
帧插值 — 使用Deforum的FILM实现在帧之间进行插值。需要Deforum扩展。#128
-
插值X — 用X个插值的输出帧替换每个输入帧。#128。
-
视频源 — [可选] 用于 ControlNet V2V 的视频源文件。您必须启用ControlNet。它将成为您启用的所有ControlNet单元的源控制,而无需提交控制图像或路径到ControlNet面板。当然,您可以通过"单个图像"选项卡提交一个控制图像,或者通过"批量"选项卡提交一个输入目录,这将覆盖此视频源输入并正常工作。
-
视频路径 — [可选] 用于 ControlNet V2V 的源帧文件夹,但比
视频源的优先级低。您必须启用ControlNet。它将成为您启用的所有ControlNet单元的源控制,而无需提交控制图像或路径到ControlNet。当然,您可以通过"单个图像"选项卡提交一个控制图像,或者通过"批量"选项卡提交一个输入目录,这将覆盖此视频路径输入并正常工作。- 对于希望修复视频的人:在ControlNet修复单元上输入一个包含两个子文件夹"image"和"mask"的文件夹。这两个子文件夹应该包含相同数量的图像。此扩展将根据相同的顺序将它们匹配在一起。使用我的 Segment Anything 扩展可以让您的生活更加轻松。
Img2GIF
您需要前往img2img并通过A1111面板提交初始帧。您还可以选择通过扩展面板提交最后一帧。
默认情况下,您的init_latent将会更改为:
init_alpha = (1 - frame_number ^ latent_power / latent_scale)
init_latent = init_latent * init_alpha + random_tensor * (1 - init_alpha)
如果您上传了最后一帧,您的init_latent将以类似的方式更改。要了解其工作原理,请阅读this code。
Motion LoRA
下载并像使用其他LoRA一样使用它们(示例:将运动lora下载到stable-diffusion-webui/models/Lora并在您的积极提示中添加<lora:v2_lora_PanDown:0.8>)。Motion LoRA仅支持V2运动模块。
Prompt Travel
编写积极的提示,按照以下示例:
第一行是头部提示,这是可选的。您可以不写或写一行或多行头部提示。
第二行和第三行用于提示插值,格式为帧编号:提示。您的帧编号应按升序排列,小于总帧数。第一帧的索引为0。
最后一行是尾部提示,这也是可选的。如果您不需要此功能,只需以常规方式编写提示。
1girl, yoimiya (genshin impact), origen, line, comet, wink, Masterpiece, BestQuality. UltraDetailed, <lora:LineLine2D:0.7>, <lora:yoimiya:0.8>,
0: closed mouth
8: open mouth
smile
ControlNet V2V
您需要前往txt2img / img2img-batch并提交源视频或帧路径。每个ControlNet将根据以下优先级查找控制图像:
-
ControlNet
Single Image标签或Batch标签。只需上传一个控制图像或一个包含控制帧的目录即可。 -
Img2img Batch标签
Input directory(如果您使用img2img batch)。如果您上传一个包含控制帧的目录,它将成为您启用而不提交控制图像或控制面板路径的所有ControlNet单元的源控制。 -
AnimateDiff
Video Source。如果您通过Video Source上传视频,它将成为您启用而不提交控制图像或控制面板路径的所有ControlNet单元的源控制。 -
AnimateDiff
Video Path。如果您通过Video Path上传帧路径,它将成为您启用而不提交控制图像或控制面板路径的所有ControlNet单元的源控制。
总帧数将被限制为您提供的所有文件夹中最少图像的数量。每个文件夹中的每个控制图像将应用于一个单个帧。如果您为ControlNet单元上传了一张单一图像,该图像将控制所有帧。
对于希望修复视频的人:输入一个包含两个子文件夹image和mask的文件夹,放置在ControlNet修复单元上。这两个子文件夹应包含相同数量的图像。此扩展将根据相同的顺序匹配它们。使用我的Segment Anything扩展可以让您的工作更加轻松。
在img2img批处理中的AnimateDiff将在v1.10.0中可用。
HotShot-XL
HotShot-XL与AnimateDiff具有相同的架构。唯一的两个区别是:
- HotShot-XL是使用8帧而不是16帧训练的。建议您为HotShot-XL设置
Context batch size为8。 - HotShot-XL的层数较少,这是因为SDXL。
虽然HotShot-XL的结构与AnimateDiff相同,但我强烈建议您不要在SDXL上使用AnimateDiff,也不要在SD1.5上使用HotShot,因为这样会导致严重的艺术效果。我决定不支持这一点,尽管对我来说并不难。
从技术上讲,AnimateDiff可用的所有功能在HotShot-XL中也可用。但我尚未测试它们所有。我已经测试了无限上下文生成和提示旅行;我尚未测试ControlNet。如果您发现任何错误,请向我报告。
这个扩展与官方的HotShot-XL扩展之间的区别在于 - 如果您使用这个扩展,您可以完全摆脱扩散器。
有关下载链接,请阅读Model Zoo。有关VRAM使用情况,请阅读VRAM。
模型库
mm_sd_v14.ckpt和mm_sd_v15.ckpt以及mm_sd_v15_v2.ckpt由@guoyww提供:Google Drive | HuggingFace | CivitAImm_sd_v14.safetensors
和mm_sd_v15.safetensors以及mm_sd_v15_v2.safetensors由@neph1提供:HuggingFace
mm_sd_v14.fp16.safetensors和mm_sd_v15.fp16.safetensors以及mm_sd_v15_v2.fp16.safetensors由@neggles提供:HuggingFacemm-Stabilized_high.pth和mm-Stabbilized_mid.pth由@manshoety提供:HuggingFacetemporaldiff-v1-animatediff.ckpt由@CiaraRowles提供:HuggingFacehsxl_temporal_layers.safetensors和hsxl_tenporal_layers.f16.safetensors由@hotshotco提供:HuggingFace
VRAM
实际的VRAM使用量取决于您的图像大小和上下文批量大小。您可以尝试减小图像大小或上下文批量大小以减小VRAM使用量。
以下是在Ubuntu 22.04、NVIDIA 4090、torch 2.0.1+cu117、H=W=512、帧数=16(默认设置)上测试的SD1.5 + AnimateDiff数据。w//w/o表示Settings/Optimization中的Batch cond/uncond已选中/未选中。
| 优化 | 带w/ | 带w/o |
|---|---|---|
| 无优化 | 12.13GB | |
| xformers/sdp | 5.60GB | 4.21GB |
| sub-quadratic | 10.39GB |
对于SDXL + HotShot + SDP,在Ubuntu 22.04、NVIDIA 4090、torch 2.0.1+cu117、H=W=512、帧数=8(默认设置)上测试,您需要8.66GB VRAM。
批量大小
WebUI上的批量大小将在内部由GIF帧数替代:1个批量生成1个完整的GIF。如果您想同时生成多个GIF,请更改批次数。
批次数与批量大小不同。在A1111 WebUI中,批次数在批量大小之上。批次数表示顺序步骤的数量,但批量大小表示并行步骤的数量。当您增加批次数时,您无需太担心,但当您增加批量大小(在此扩展中为视频帧号)时,您需要关注您的VRAM。使用此扩展时,您根本不需要更改批量大小。
我们目前正在开发一种方法,以在不久的将来支持WebUI上的批量大小。
基础使用效果展示
| AnimateDiff | Extension | img2img |
|---|---|---|
 |
 |
 |
Motion LoRA 效果展示
| No LoRA | PanDown | PanLeft |
|---|---|---|
 |
 |
 |
Prompt Travel 效果展示

The prompt is similar to above.
捐赠
感谢老板请我喝杯咖啡!Thank you for buying me a coffee!
| AliPay | PayPal | |
|---|---|---|
 |
 |
PayPal |
公众号: 无限递归

Copyright © 2017 - 2025 boboidea.com All Rights Reserved 波波创意软件工作室 版权所有 【转载请注明出处】